Building a Stock Screener in Python- Part 2
In this series, I’ll share how to create a stock screener — a program which can filter stocks based on user preferences — from scratch (and for free) using python. This project will be broken into 3 parts-
- Scraping data
- Storing data
- Screening data
If you haven’t already, check out Part 1 where I talk about scraping stock information from Yahoo Finance in under 10 minutes! In this part, we’ll focus on storing the data we’ve collected and preparing it for screening.
Recap- Scraping
In the last part, we built a web scraper to crawl through yahoo finance and collect information about companies we’re interested in. We utilized BeautifulSoup library to create the scraper and were successfully able to scrape data.
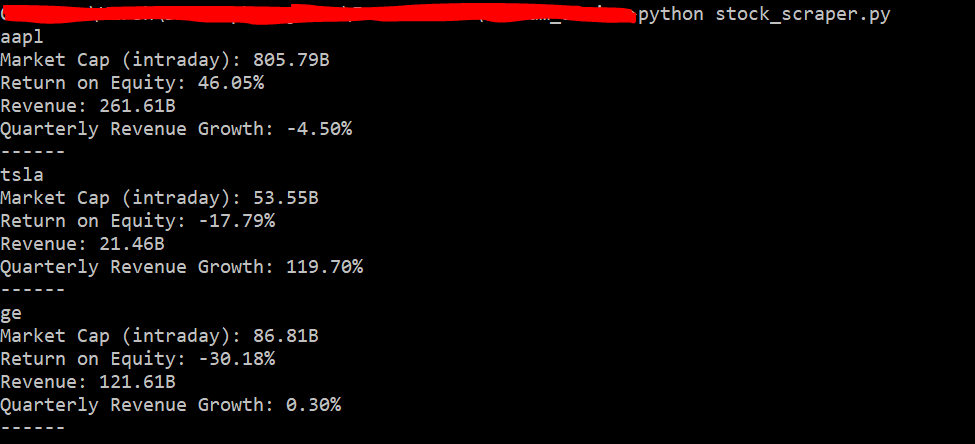
Example from the first part scraping information about Apple, Tesla and GE
Pieces
We’ll be storing the information from the stock scraper in a format which is user-friendly and ready for screening. To do this, we’ll need two things-
- List of companies to get data for
- List of indicators to collect data for
We eventually want to use this stored data to screen companies to invest in, so we first want a list of companies that we’re interested in. For me, I found the constituents of the S&P 500, which consists of 500 of the largest U.S. publicly traded companies. You can chose to use your own list, but if you want to use the S&P 500 as well, here’s a link.
We also need a list of indicators to collect data. Indicators are metrics used to predict the direction of major financial indexes or groups of securities. In my case, here’s the list of indicators which I chose-
‘Market Cap (intraday)’, ‘Return on Equity’, ‘Revenue’, ‘Quarterly Revenue Growth’, ‘Operating Cash Flow’, ‘Total Cash’, ‘Total Debt’, ‘Current Ratio’, ‘52-Week Change’, ‘Avg Vol (3 month)’, ‘Avg Vol (10 day)’, ‘% Held by Insiders’
You can find the full list of indicators on the Yahoo Finance page for a security.
Code
We’re going to utilize the scraper we built in the last part, along with the list of companies and indicators as discussed above. The code for storing this data is fairly straightforward and I explain it thoroughly below.
The first part of the code create a list of companies to look at from a .csv file in the folder, which contains symbols, names and industries of companies we’re interested in. We then create an array of strings with the names of all the indicators we’re interested in.
After this, we’ll be creating an empty pandas data frame with the columns set to the indicators to store the information about the companies. Now, similar to the previous part, we’ll iterate through the list of companies, and each indicator. For each company we’ll scrape data using our scrape_yahoo method. We’ll store the data collected in our data frame and at the end print out a message when the data is stored to keep track of our progress. Our job is not done yet though, we still need to clean the data!
We’ll clean the data in 3 steps. We’ll rename the first column in the data frame to “Symbol” as it contains the ticker symbol for each of our companies. Then, we’ll join our new data frame with the old symbols data frame to ensure we keep the full name and industry of the company as well. Last, we’ll drop rows with excessive NaN values. When web scraping, there’s a fair possibility to have some missing data and dropping rows with excessive missing values(<10 non-NaN values) will be helpful later. After this, we can save our pandas data frame to a .csv file.
The full code for this data storage program can be found on this github repository.
Wrap up and what next?
So now you have it! A way to store scraped stock data off of Yahoo Finance for use in your very own stock screener. If you want to continue on in this series, feel free to check out Part 3 (coming in Mar. 2019). In part 3 we’ll build upon this algorithm and create a screening pipeline to select companies which match our criteria.
ที่มาบทความ : Medium.com.
