Web Scraping NBA Stats
Every data analysis starts with an idea, hypothesis, problem, etc. The next step usually involves the most important element: data. Today, data is everywhere. For those of us who love diving into data, there are lots of resources to attain this part of the process. Whether it’s through Kaggle or UCI Machine Learning Repository, data is easily available. However, sometimes not all data is available to us. Sometimes, in order to continue a certain data analysis/project, we must do a bit more to get the correct, updated data we need.
This brings us to our topic: web scraping to create a data set. A while back, I worked on a basketball analytics project. The project was an analysis on individual stats of NBA players, and using some of those stats to predict win shares for the 2018 NBA season. As I began the project, I realized that the NBA data sets available on Kaggle did not have all the stats I needed to continue my analysis. Therefore, I decided to do a bit more research.
First of all, my go-to site for all NBA stats is Basketball Reference. This site is essentially an encyclopedia for all things NBA stats. Then came my next question: Why not get the data directly from the Basketball Reference? After further research, I discovered a great Python library that solved this portion of my project:BeautifulSoup . This library is a web scraper that allows us to search through the HTML of a webpage and extract the information we need. From there, we will store the data we scraped onto a DataFrameusing pandas.
First, let’s get all the Python libraries we will be using for this project:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
Now, we determine the HTML page we will be scraping. For this part, I used the individual per game stats of players for the current 2018–2019 NBA season. The page on Basketball Reference looks like this:

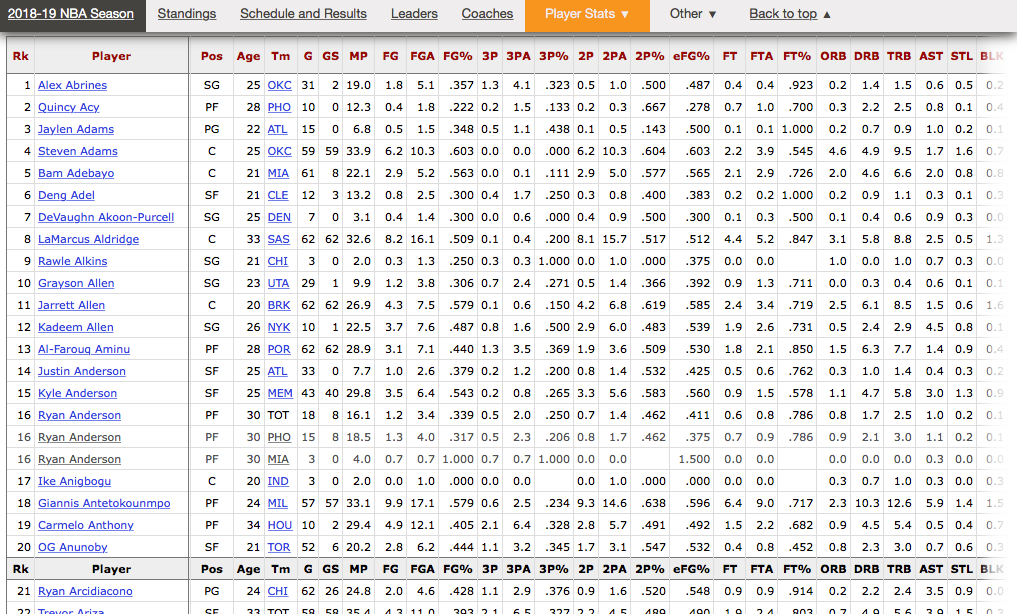
As you can see, the data is already organized into a table. This makes web scraping a lot easier! Now we will use urlopen that we imported from the urllib.request library, then create a BeautifulSoup object by passing through html to BeautifulSoup().
_# NBA season we will be analyzing
year = 2019_# URL page we will scraping (see image above)
url = "https://www.basketball-reference.com/leagues/NBA_{}_per_game.html".format(year)_# this is the HTML from the given URL_
html = urlopen(url)soup = BeautifulSoup(html)
Here, the BeautifulSoup function passed through the entire web page in order to convert it into an object. Now we will trim the object to only include the table we need.
The next step is to organize the column headers. We want to extract the text content of each column header and store them into a list. We do this by inspecting the HTML (right-clicking the page and selecting “Inspect Element”) we see that the 2nd table row is the one that contains the column headers we want. By looking at the table, we can see the specific HTML tags that we will be using to extract the data:


Now, we go back to BeautifulSoup. By using findAll(), we can get the first 2 rows (limit = 2) and pass the element we want as the first argument, in this case ‘_tr_’, which is the HTML tag for table row. After using findAll(), we use the getText() to extract the table header, or ‘_th_’, text we need and organize it into a list:
# use findALL() to get the column headers
soup.findAll('tr', limit=2)# use getText()to extract the text we need into a list
headers = [th.getText() for th in soup.findAll('tr', limit=2)[0].findAll('th')]# exclude the first column as we will not need the ranking order from Basketball Reference for the analysis
headers = headers[1:]
headers

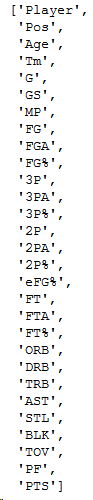
Next step, we will extract the data from the cells of the table in order to add it to our DataFrame. Although it is similar to extracting data from column header, the data within the cell, in this case player stats, is in a 2-dimensional format. Therefore, we must set up a 2-dimensional list:
# avoid the first header row
rows = soup.findAll('tr')[1:]
player_stats = [[td.getText() for td in rows[i].findAll('td')]
for i in range(len(rows))]
Now comes something a bit more familiar: pandas. With the data and columns headers we have extracted from Basketball Reference, we create a simple DataFrame:
stats = pd.DataFrame(player_stats, columns = headers)
stats.head(10)

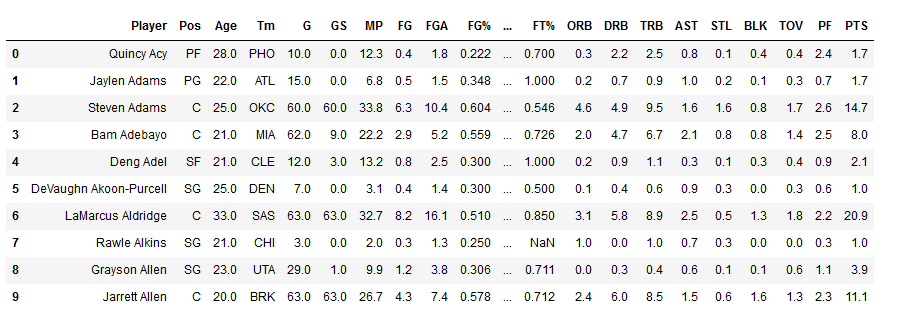
Voilà! We have our own data set! In a matter of minutes, we analyzed an HTML document, extracted the data from the table, and organized it onto a DataFrame. For free! And without any hassle of searching for a .csv file that might not be up-to-date. We have data that comes directly from a source that is updated everyday. Of course, not every HTML document is created equally. There are pages that might require a bit more time in analyzing the HTML tags in order to extract the proper data.
To conclude this quick walk through, web scraping can be a simple task, but for certain HTML documents, it can be difficult. There are a bunch of helpful resources out there that will help you understand HTML tags, and get the data you need. There might be a problem you want to dive into, so don’t let limited data be an issue!
